0. 메모리 주소
물리 주소 (Physical Address)
- 데이터와 명령어가 실제로 저장되는 하드웨어 상의 주소
- 낮은 주소 영역에는 운영체제가, 높은 주소 영역에는 사용자 프로세스가 적재됨
논리 주소 (Logical Address)
- 프로세스마다 독립적으로 가지는 주소 공간 (= 가상 메모리)의 주소
- 프로세스마다 0번지부터 시작
- CPU는 물리 주소가 아닌 논리 주소에 근거해 명령어를 해석 및 실행
1. 주소 바인딩 (Address Binding)

논리 주소를 물리 주소로 변환하는 과정
- CPU가 메모리와 상호작용하려면 논리 주소는 물리 주소로 변환되어야 하며 이것을 주소 바인딩이라고 함
Compile Time Binding
- 컴파일 시점에 물리 주소가 결정되는 방식
- 프로그램이 적재된 물리 주소를 변경하고 싶다면 재컴파일이 필요함
Load Time Binding
- 실행 시점에 물리 주소가 결정되는 방식
- 프로그램이 종료될 때까지 로더의 책임하에 물리 주소가 고정됨
→ 로더 (Loader) : 사용자 프로그램을 메모리에 적재시키는 프로그램
Execution Time Binding (= Run Time Binding)
- 현대 대부분의 운영체제가 채택
- 프로그램 실행 중 물리 주소가 변경될 수 있는 방식
- 그러므로 CPU가 논리 주소를 참조할 때마다 주소 바인딩이 필요
- 이는 하드웨어적 지원이 필요하므로 MMU가 등장
2. MMU (Memory Management Unit)

주소 바인딩을 수행하는 하드웨어 장치
- 베이스 레지스터 (Base Register)
→ 프로세스의 시작 물리 주소를 저장
→ 문맥 교환으로 CPU가 실행 중인 프로세스가 바뀔 때마다 베이스 레지스터의 값을 그 프로세스에 해당하는 값으로 재설정 - 한계 레지스터 (Limit Register)
→ 논리 주소의 최댓값 즉, 프로세스의 최대 크기를 저장
→ 논리 주소 범위를 벗어나는 명령어 실행으로부터 보호
→ CPU가 한계 레지스터보다 높은 논리 주소에 접근하려고 하면 Trap을 발생시켜 해당 프로세스를 강제 종료시킴
MMU는 CPU가 발생시킨 논리 주소에 베이스 레지스터값을 더하여 논리 주소를 물리 주소로 변환
- MMU 기법에서 사용자 프로그램이나 CPU는 논리 주소만을 다룰 뿐, 물리 주소는 알지 못하며 알아야 할 필요도 없음
3. 여러 가지 용어
Dynamic Loading
- 프로세스 전체를 메모리에 미리 다 적재하는 것이 아닌, 해당 루틴이 호출될 때 메모리에 적재하는 것
→ 메모리 이용 효율성 향상 - 운영체제의 특별한 지원 없이 프로그램 자체에서 구현 가능
→ 운영체제가 라이브러리를 통해 지원
Overlays
- Dynamic Loading과 개념적으로 동일하나, 과거 메모리 용량 부족으로 인해 프로그래머가 직접 구현하던 것을 의미
Swapping
- 사용되지 않는 프로세스를 임시로 보조기억장치의 스왑 영역으로 쫓아내고, 그렇게 해서 생긴 메모리상의 빈 공간에 또 다른 프로세스를 적재하여 실행하는 방식
- 일반적으로 Swapper (중기 스케줄러)에 의해 수행됨
→ Swap-In : 메모리 ← 스왑 영역
→ Swap-Out : 메모리 → 스왑 영역 - Swap Time은 대부분 Transfer Time이 차지
Linking
- 컴파일러가 만들어낸 하나 이상의 목적 파일을 단일 실행 파일로 병합하는 과정
- Static Linking
→ 라이브러리가 프로그램의 실행 파일 코드에 포함됨
→ 실행 파일의 크기가 커짐
→ 동일한 라이브러리를 각각의 프로세스가 메모리에 적재하므로 메모리가 낭비됨 - Dynamic Linking
→ 라이브러리가 프로그램 실행 시 연결됨
→ 라이브러리 호출 부분에 해당 라이브러리의 위치를 찾기 위한 Stub이라는 작은 코드 조각이 위치함
→ 라이브러리가 이미 메모리에 적재되어있다면 해당 라이브러리의 라이브러리 루틴 사용
→ 라이브러리가 메모리에 없다면 보조기억장치에서 라이브러리를 읽어와 메모리에 적재 후 라이브러리 루틴 사용
→ 운영체제의 도움이 필요
4. 메모리 할당
프로세스는 메모리 내의 빈 공간 (Hole)에 적재되어야 한다. 빈 공간이 여러 개 있다면 프로세스를 어디에 적재할 것인가?
최초 적합 (First Fit)
- 운영체제가 메모리 내의 빈 공간을 순서대로 검색하다가 적재할 수 있는 공간을 발견 시 해당 공간에 적재
최적 적합 (Best Fit)
- 운영체제가 메모리 내의 빈 공간을 모두 검색한 후, 프로세스가 적재될 수 있는 공간 중 가장 작은 공간에 적재
최악 적합 (Worst Fit)
- 운영체제가 메모리 내의 빈 공간을 모두 검색한 후, 프로세스가 적재될 수 있는 공간 중 가장 큰 공간에 적재
5. 연속 메모리 할당 & 불연속 메모리 할당
연속 메모리 할당
- 각각의 프로세스를 메모리의 연속적인 공간에 적재하는 방식
연속 메모리 할당 - 고정분할 방식
- 메모리를 특정 개수의 영구적 분할로 미리 나누어 놓음 (융통성 X)
→ 분할의 크기는 모두 동일할 수도, 서로 다를 수도 있음 - 하나의 분할 당 하나의 프로그램을 적재
- 외부 단편화 O / 내부 단편화 O
→ 외부 단편화 : 분할 외부에 hole이 발생하는 상황
→ 내부 단편화 : 분할 내부에 hole이 발생하는 상황
연속 메모리 할당 - 가변분할 방식
- 메모리를 프로그램의 크기를 고려해서 할당하는 방식
- 분할의 크기 및 개수가 동적으로 변함
- 외부 단편화 O / 내부 단편화 X
→ 압축 : 메모리 내의 프로세스를 재배치시켜 흩어져있는 빈 공간을 하나로 모아 외부 단편화를 해결 (오버헤드가 크며 오버헤드 최소화에 대한 명확한 방법을 결정하기 어려움)
불연속 메모리 할당
- 하나의 프로세스를 메모리의 불연속적인 공간에 적재하는 방식
- 현대 대부분의 운영체제가 채택
- 예) Paging, Segmentation, Paged Segmentation
6. 페이징
메모리의 물리 주소 공간을 프레임이라는 일정한 단위로 자르고, 프로세스의 논리 주소 공간을 페이지라는 프레임과 동일한 크기의 일정한 단위로 자른 뒤 페이지를 프레임에 할당하는 방식
단편화
- 외부 단편화 X (페이지의 크기가 동일하기 때문)
- 내부 단편화 O (프로세스의 크기가 페이지의 배수라는 보장이 없기 때문)
페이지 테이블
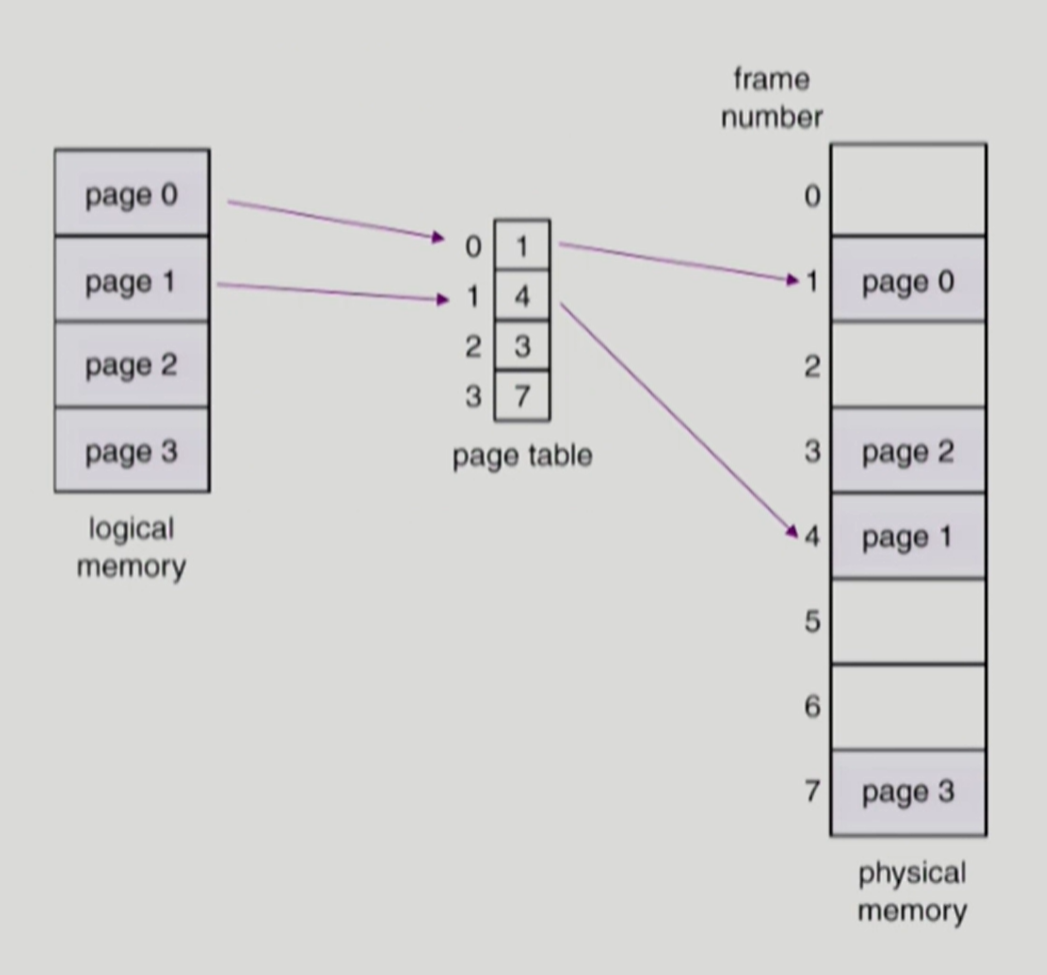
- 프로세스가 메모리에 불연속적으로 배치되어 있다면 CPU 입장에서 이를 순차적으로 실행할 수 없음
- 이를 해결하기 위해 각 페이지 번호에 해당하는 프레임 번호를 매핑시켜주는 페이지 테이블이 존재
→ 페이지 번호가 곧 페이지 테이블의 인덱스 - 페이지 테이블은 메모리 내부에 존재하며 프로세스마다 각자의 페이지 테이블을 가짐
- 페이지 테이블 베이스 레지스터 (Page Table Base Register, PTBR)
→ 각 프로세스의 페이지 테이블의 시작 주소를 저장
→ CPU 내부에 존재 - 페이지 테이블 길이 레지스터 (Page Table Length Register, PTLR)
→ 각 프로세스의 페이지 테이블의 크기를 저장
→ CPU 내부에 존재
MMU의 페이지 테이블을 통한 주소 바인딩 과정
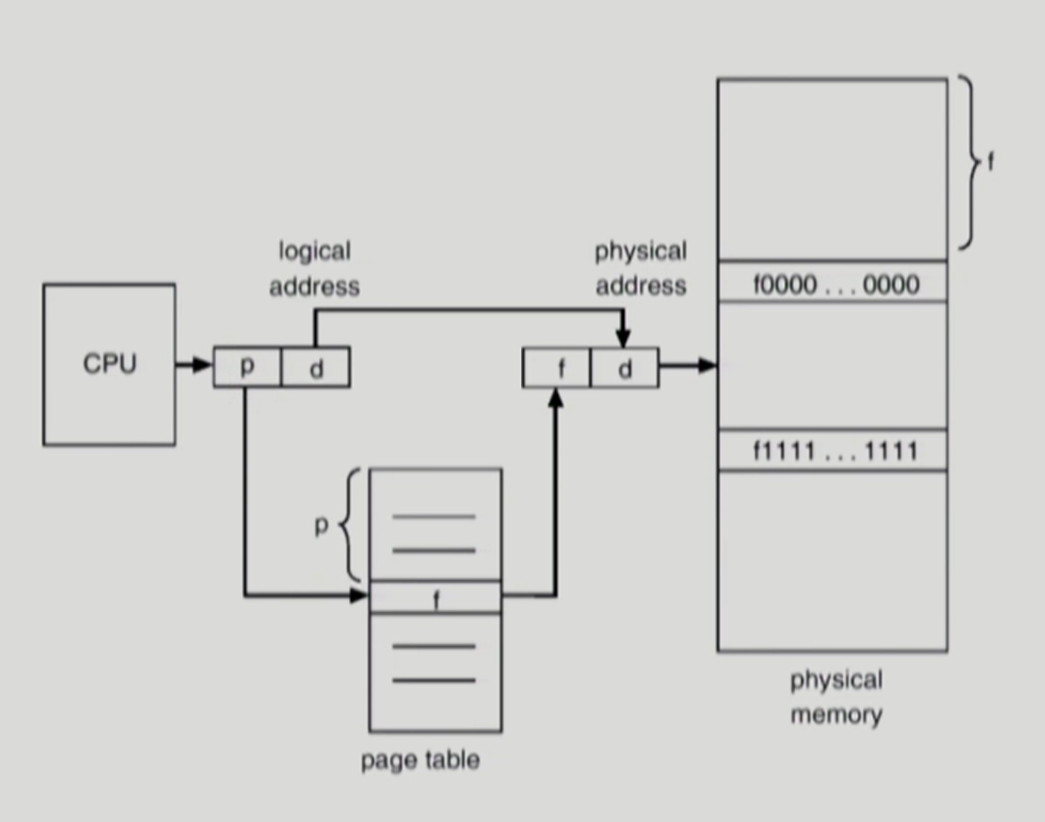
- 페이징 시스템에서는 모든 논리 주소가 기본적으로 <페이지 번호, 변위>의 형식으로 이루어짐
→ 변위 (Offset) : 접근하려는 주소가 시작 주소로부터 얼마나 떨어져 있는지를 알기 위한 정보
→ 논리 주소에서의 변위와 물리 주소에서의 변위는 일치 - 논리 주소 <페이지 번호, 변위>를 페이지 테이블을 통해 물리 주소 <프레임 번호, 변위>로 변환
→ 페이지 번호 p가 PTLR 값보다 크다면 Trap 발생
페이지 테이블의 단점
- 두 번의 메모리 접근이 필요함
→ 1. 메모리 내부의 페이지 테이블에 접근
→ 2. 페이지 테이블을 통해 페이지 번호에 해당하는 프레임에 접근 - 이를 해결하기 위해 TLB가 등장
TLB (Translation Lookaside Buffer)
- 페이지 테이블의 캐시 메모리
→ 고속의 하드웨어
→ 참조 지역성의 원리에 근거하여 엔트리를 캐싱
→ 문맥 교환 발생 시 새 프로세스의 페이지 테이블을 캐싱하기 위해 flush - 페이지 테이블과 TLB에 저장되어있는 정보의 구조는 다름
→ 페이지 테이블과 달리 프로세스의 모든 페이지에 대한 주소 변환 정보를 가지고 있지 않음
→ 그러므로 페이지 번호와 이에 대응하는 프레임 번호가 쌍으로 저장되어야 함 - 또한 특정 페이지에 대한 주소 변환 정보를 확인하기 위해 모든 엔트리를 다 찾아봐야 하는 오버헤드가 발생
→ 이를 해결하기 위해 병렬 탐색이 가능한 연관 레지스터를 사용
MMU의 TLB를 통한 주소 바인딩 과정
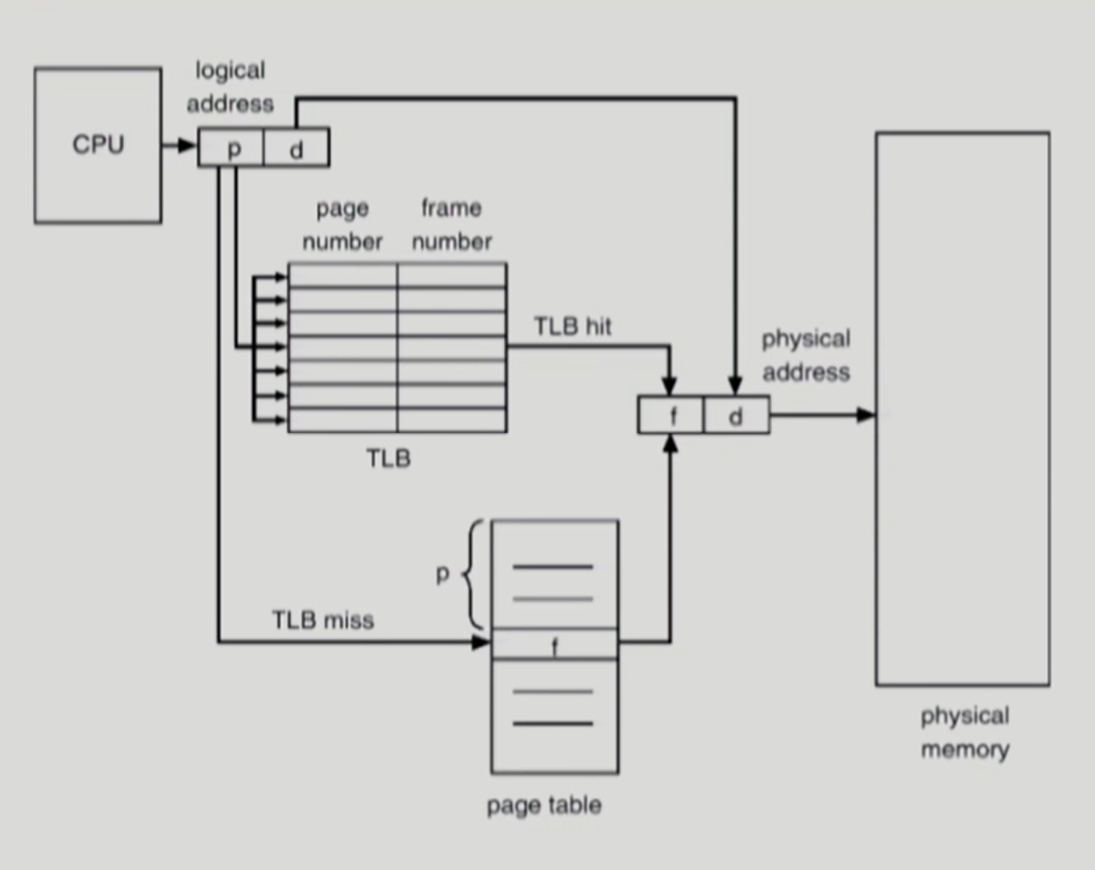
- TLB Hit
→ 논리 주소의 페이지 번호가 TLB에 있을 경우 해당 페이지 번호에 해당하는 프레임 번호를 통해 물리 주소로 변환 - TLB Miss
→ 논리 주소의 페이지 번호가 TLB에 없을 경우 페이지 테이블을 통해 물리 주소로 변환
7. 계층적 페이징
페이지 테이블을 페이징하여 여러 단계의 페이지를 두는 방식
- Inner 페이지 테이블
→ 여러 개의 페이지로 페이징 된 페이지 테이블 - Outer 페이지 테이블
→ Inner 페이지 테이블을 가리키는 페이지 테이블 - 더 이상 모든 페이지 테이블 엔트리를 메모리에 유지할 필요가 없음
→ Inner 페이지 테이블의 경우 필요 없는 페이지 테이블은 보조기억장치에 저장 후 필요시 메모리에 적재하면 됨
→ Outer 페이지 테이블의 경우 항상 메모리에 있어야 함
등장 배경
- 현대의 컴퓨터는 주소 공간이 매우 큰 프로그램을 지원
- 프로세스의 크기가 커질수록 페이지 테이블의 크기도 커짐
- 대부분의 프로세스는 자신의 메모리 영역 중 지극히 일부만 사용
- 그러므로 프로세스를 이루는 모든 페이지 테이블 엔트리를 메모리에 두는 것은 메모리 낭비
- 계층적 페이징 등장
2단계 페이징
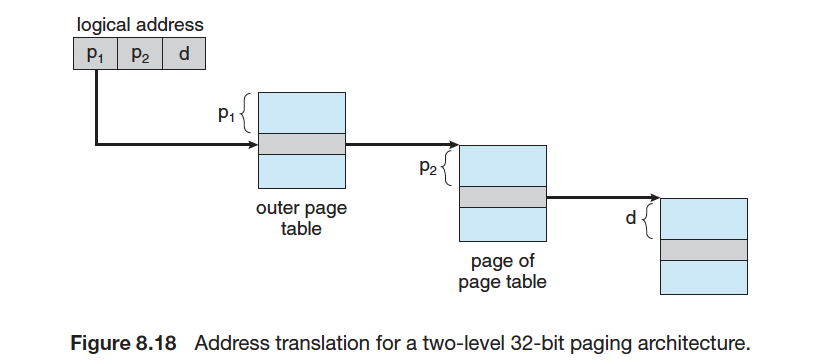
- 2단계 페이징 시스템에서는 논리 주소가 <외부 페이지 번호, 내부 페이지 번호, 변위>의 형식으로 이루어짐
→ 외부 페이지 번호 : Outer 페이지 테이블에서의 변위
→ 내부 페이지 번호 : Inner 페이지 테이블에서의 변위 - 주소 바인딩 과정
→ 1. 외부 페이지 번호를 통해 페이지 테이블의 페이지 (Inner 페이지 테이블)를 찾음
→ 2. 내부 페이지 번호를 통해 프레임 번호를 찾고 변위를 더함으로써 물리 주소 획득 - 메모리 낭비를 어떻게 줄이는가?
→ 사용하지 않는 주소 공간에 대해서는 외부 페이지 테이블의 엔트리를 NULL로 설정
다단계 페이징
- 주소 공간이 더 커지면 다단계 페이징이 필요한 상황이 발생
- 페이지 테이블의 계층이 늘어날수록 메모리 참조 횟수가 증가
→ TLB를 통해 메모리 접근 시간을 줄일 수 있음
8. 페이징 - 그 외
페이지 테이블의 엔트리에는 페이지 번호, 프레임 번호 이외에도 다른 중요한 정보들이 있음
유효 비트 (Valid Bit)
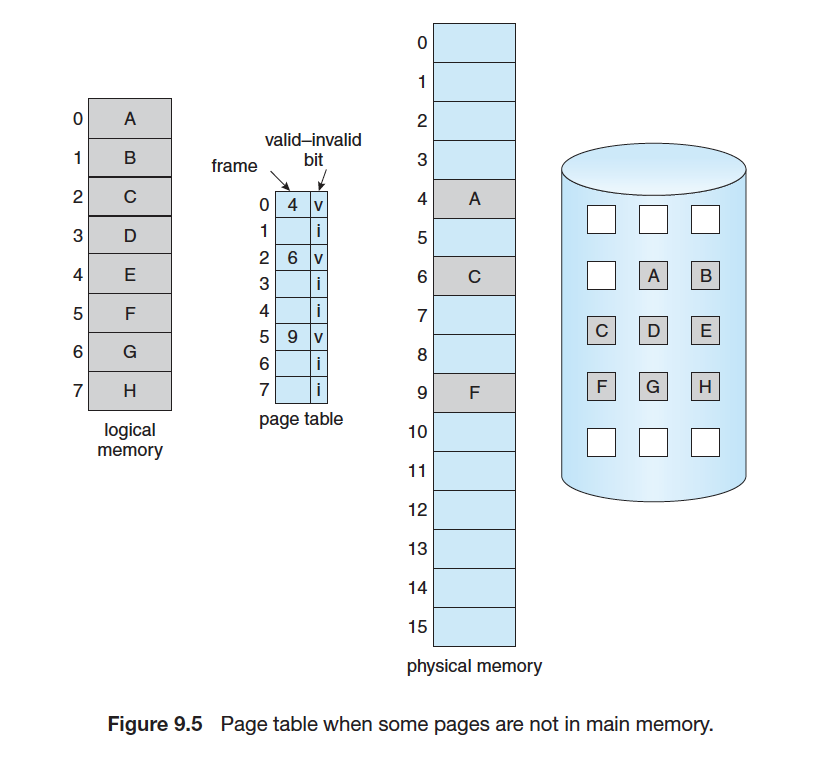
- 현재 해당 페이지에 접근 가능한지에 대한 여부를 저장
→ 유효 비트 0 : 페이지가 메모리에 적재되어 있지 않은 상황 (+ 프로세스가 해당 페이지를 사용하지 않는 상황)
→ 유효 비트 1 : 페이지가 메모리에 적재된 상황
보호 비트 (Protection Bit)
- 한 프로세스의 주소 공간은 다른 프로세스에 의해 접근될 수 없으므로 '누구'에 해당하는 접근 권한을 설정할 필요는 없으며, 각 페이지에 대해 '어떠한' 접근을 허용하는지의 정보를 저장
→ 보호 비트 0 : Read Only
→ 보호 비트 1 : Read & Write - Read Only 페이지에 Write 시도 시 운영체제가 이를 보호
→ 예) 프로세스 메모리 영역 중 Code 영역은 Read Only 영역
그 외에도 참조 비트 (Reference Bit, Dirty Bit), 수정 비트 (Modified Bit) 등이 존재
- 참조 비트 : CPU가 이 페이지에 접근한 적이 있는지에 대한 여부를 저장
- 수정 비트 : 해당 페이지에 데이터를 Write한 적이 있는지에 대한 여부를 저장
→ 페이지가 메모리에서 사라질 때 보조기억장치에 Write를 해야 하는지, 할 필요가 없는지를 판단하기 위해 존재
역 페이지 테이블 (Inverted Page Table)
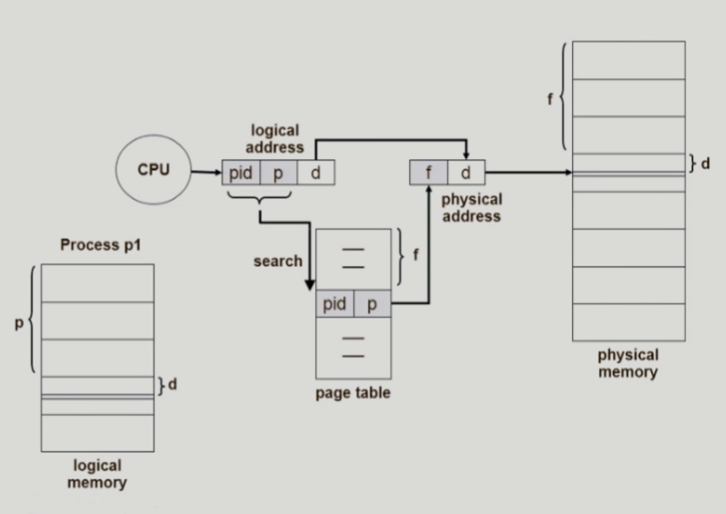
- 페이지 테이블의 역할을 역전시킴
→ 각 프레임 번호에 해당하는 페이지 번호를 매핑시켜주는 페이지 테이블
→ 역 페이지 테이블은 메모리 내부에 하나만 존재 - 장점 : 프로세스 증가가 페이지 테이블의 증가로 이어지지 않아 메모리 활용 효율성 증가
- 단점 : 최악의 경우 페이지 테이블 전체 탐색이 필요하므로 성능 저하 발생 가능
공유 페이지 (Shared Page)
- 여러 프로세스에 의해 공유되는 공유 코드를 담고 있는 페이지
→ 공유 코드는 재진입 가능 코드, 순수 코드라고도 불림
→ Read Only
→ 메모리에 하나만 적재되어 효율적 - 공유 페이지는 자신을 공유하는 모든 프로세스의 논리 주소 공간에서 동일한 페이지 번호를 가져야 함
9. 세그멘테이션 (Segmentation)
프로세스의 논리 주소 공간을 의미 단위인 여러 개의 세그먼트로 구성하는 방식
- 세그먼트는 페이지와 달리 정해진 크기가 아님
- 일반적으로 Code, Data, Stack 영역을 각각 하나의 세그먼트로 정의
- 크게는 프로세스 전체를 하나의 세그먼트로 정의
- 작게는 프로세스를 구성하는 함수를 하나의 세그먼트로 정의
단편화
- 외부 단편화 O (세그먼트의 크기가 동일하지 않기 때문)
- 내부 단편화 X (세그먼트의 크기가 동일하지 않기 때문)
세그먼트 테이블
- 페이징 기법에서는 모든 페이지의 크기가 동일하므로, 페이지 테이블의 엔트리에 프레임 번호만 유지
- 세그멘테이션 기법에서는 세그먼트의 크기가 동일하지 않으므로, 세그먼트 테이블의 엔트리에 base와 limit (세그먼트 크기)를 유지
- 세그먼트 테이블 베이스 레지스터 (Segment Table Base Resister, STBR)
→ 각 프로세스의 세그먼트 테이블의 시작 주소를 저장
→ CPU 내부에 존재 - 세그먼트 테이블 길이 레지스터 (Segment Table Length Resister, STLR)
→ 각 프로세스의 세그먼트 테이블의 크기를 저장
→ CPU 내부에 존재
MMU의 세그먼트 테이블을 통한 주소 바인딩 과정
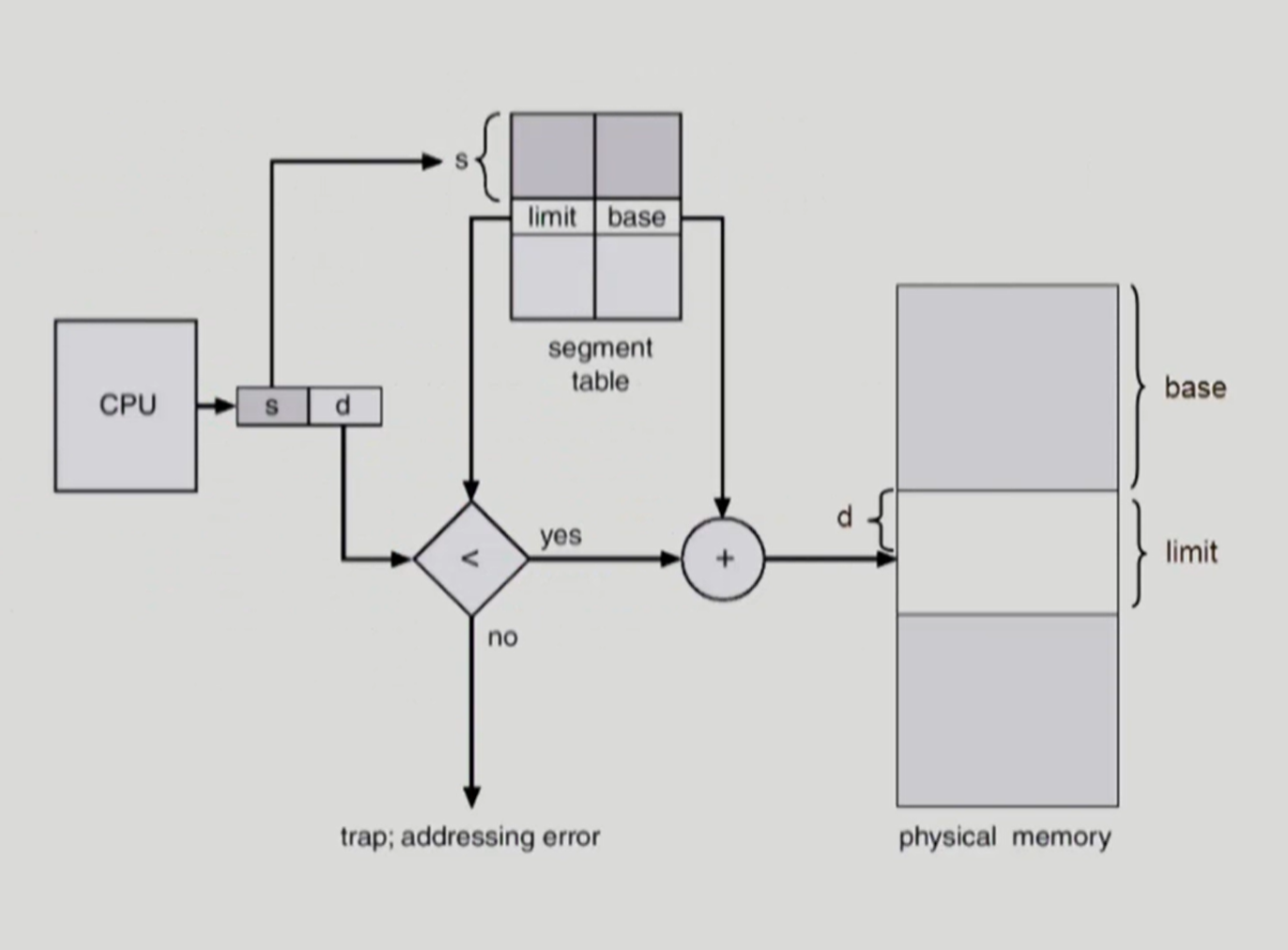
- 세그멘테이션 시스템에서는 모든 논리 주소가 기본적으로 <세그먼트 번호, 변위>의 형식으로 이루어짐
- 논리 주소 <세그먼트 번호, 변위>를 세그먼트 테이블을 통해 물리 주소 <프레임 번호, 변위>로 변환
→ 세그먼트 번호 s가 STLR 값보다 크다면 Trap 발생
→ 변위 d가 limit보다 크다면 Trap 발생
장점
- 세그먼트는 의미 단위이기 때문에 공유와 보안에 있어 페이징보다 효과적
- 일반적으로 세그멘테이션이 페이징보다 테이블로 인한 메모리 낭비가 적음
10. Paged Segmentation
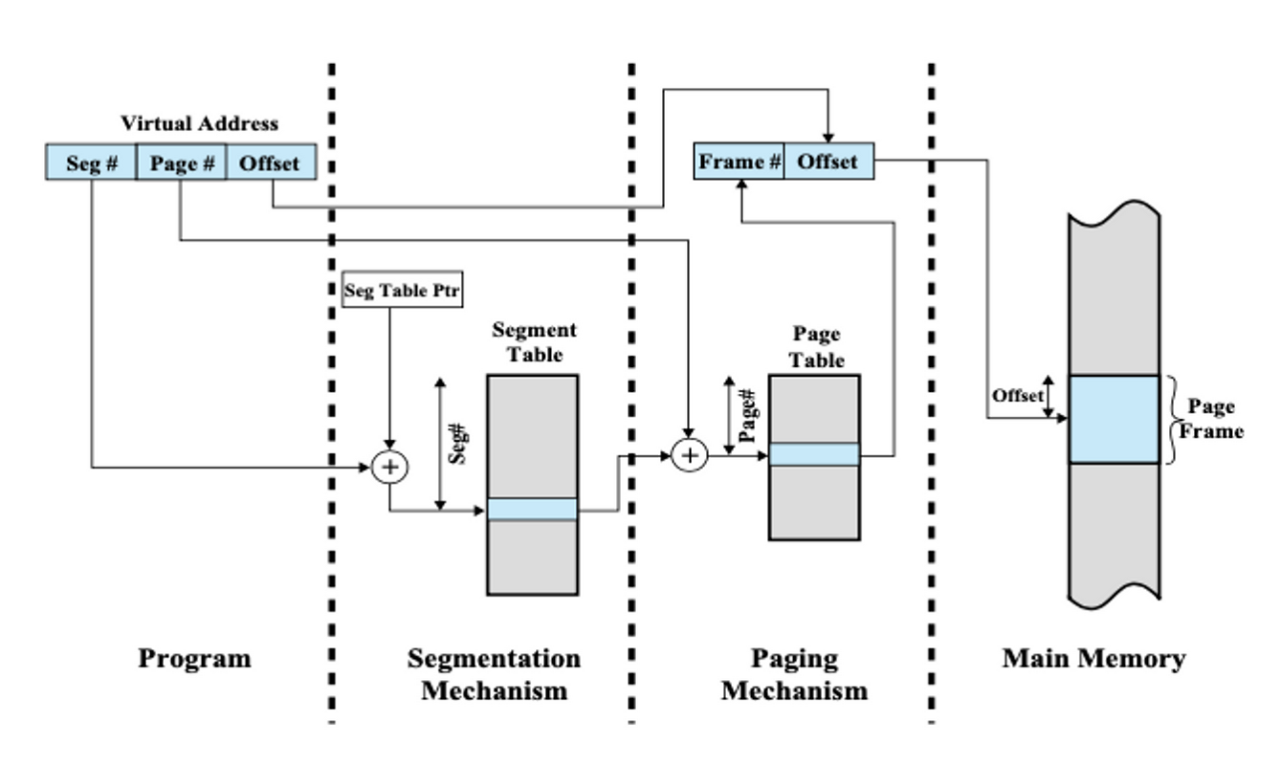
세그멘테이션을 먼저 수행하고 각 세그먼트 별로 페이징을 수행하는 방식
- 즉, 세그먼트 하나가 여러 개의 페이지로 구성됨
단편화
- 외부 단편화 X
- 내부 단편화 O
이화여자대학교 반효경 교수님의 운영체제 강의를 정리한 글입니다.
http://www.kocw.net/home/cview.do?cid=3646706b4347ef09
운영체제
운영체제는 컴퓨터 하드웨어 바로 위에 설치되는 소프트웨어 계층으로서 모든 컴퓨터 시스템의 필수적인 부분이다. 본 강좌에서는 이와 같은 운영체제의 개념과 역할, 운영체제를 구성하는 각
www.kocw.net
또한 반효경 교수님의 "운영체제와 정보기술의 원리" 책을 참고하였습니다.
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=238716482
운영체제와 정보기술의 원리
온라인 공개강좌 KOCW에서 꾸준히 호평받아온 이화여대 반효경 교수의 컴퓨터 입문서이다. 단순히 컴퓨터 관련 전문 지식을 전달하는 것에서 그치지 않고, 복잡한 문제를 효율적으로 풀 수 있는
www.aladin.co.kr
'OS' 카테고리의 다른 글
| 10. 파일 시스템 (0) | 2024.01.23 |
|---|---|
| 9. 가상 메모리 (0) | 2024.01.19 |
| 7. 교착 상태 (Deadlock) (0) | 2024.01.09 |
| 6. 프로세스 동기화 (0) | 2024.01.03 |
| 5. CPU 스케줄링 (0) | 2023.12.30 |